
Rate Limiting is a common requirement for any API service to protect itself from malicious or accidental abuse. Aperture provides a powerful policy engine that can be used to implement rate limiting using the Rate Limiter Component and Flow Classifier.
In this blog post, we will specifically examine how to implement rate limiting for GraphQL queries. Let us begin by discussing what GraphQL is and why rate limiting on GraphQL queries is required.
What is GraphQL?
GraphQL is a query language for APIs and a runtime for fulfilling those queries with existing data. It was developed and open-sourced by Facebook. GraphQL provides a complete and understandable description of the data in an API, allowing clients to request exactly what they need and nothing more. This makes it easier to evolve APIs over time and enables powerful developer tools.
A GraphQL API has a single endpoint that responds to requests. The client specifies the shape of the data it needs, and the server responds with the requested data. This allows the client to have more control over the data it receives and minimizes the amount of data transferred over the network, as the server only sends back the requested data. In addition to requesting specific data, GraphQL also allows for mutations, which are operations that modify data on the server.
One of the main benefits of GraphQL is that it allows the client to request exactly the data it needs, and nothing more. This makes it well-suited for modern, data-driven applications that need to be flexible and responsive to changing requirements. It also allows the server to evolve its API over time without breaking existing clients.
GraphQL has become a popular choice for building APIs because it provides an efficient, powerful, and flexible alternative to REST and ad-hoc web service architectures.
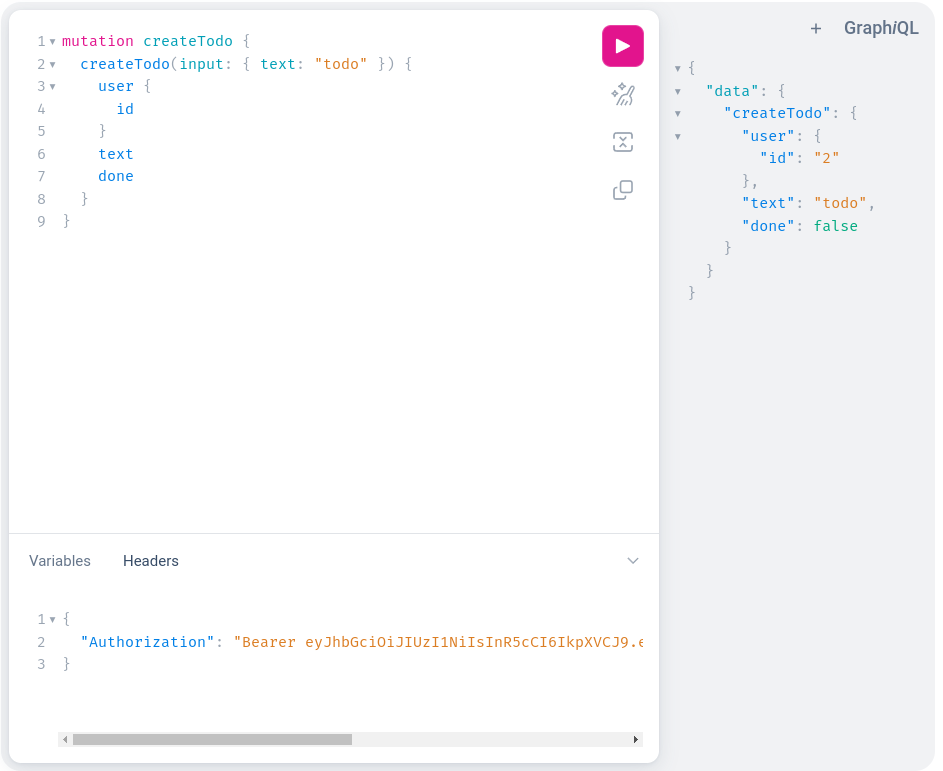
Here is an example of a GraphQL query that creates a new 'To-Do' item and its corresponding response:
What is Rate Limiting?
Rate limiting is a mechanism to control the rate of requests to a service. It is used to protect the service from being overwhelmed by too many requests. Rate limiting can be implemented in different ways depending on the use case. For example, a service can be rate limited based on the number of requests per second, per minute, per hour, per day, and so on. Rate limiting can also be implemented based on the number of requests per user, per IP address, per API key, and so on.

With the growing popularity of GraphQL, it is becoming increasingly important to implement rate limiting for GraphQL queries. This is because GraphQL queries can be nested and can contain multiple mutations and queries, making it difficult to implement rate limiting at the application level. In addition, GraphQL queries can be made by multiple clients at the same time, which can cause the service to be overwhelmed by too many requests.
Aperture's Distributed Rate Limiter
A distributed rate limiter is a system that is used to limit the number of requests that a client can make to a server over a specified time period. It is called "distributed" because it is implemented across a distributed system, such as a cluster of servers, rather than on a single server.
Distributed rate limiters are used to prevent a single client or group of clients from overloading a server with too many requests, which can degrade the performance of the server and prevent it from serving other clients. They are also used to protect servers from denial-of-service (DoS) attacks, which involve numerous requests being made in a short period of time in an attempt to overwhelm the server.
There are several algorithms that can be used to implement a distributed rate limiter, such as the token bucket algorithm and the leaky bucket algorithm. These algorithms work by allowing a certain number of requests to be made within a specified time period, and then limiting or blocking additional requests until the time period has expired. The specific implementation of a distributed rate limiter will depend on the requirements of the system it is being used in.
This technique has the following advantages over a centralized rate limiter:
- Scalability: Ability to scale horizontally so that they can handle increasing load and capacity by adding more nodes to the system.
- Fault tolerance: More fault-tolerant, so that they can continue to operate even if one or more nodes fail or become unavailable.
- Performance: High-performing, so that they can retrieve and store data quickly and efficiently.
Aperture is an open source flow control and reliability management platform for modern web applications. As part of its sophisticated flow control capabilities, Aperture provides a distributed rate limiter that can be used to implement rate limiting.
You can read more about Aperture here.
The distributed rate limiter in Aperture is implemented as a circuit component that can be used to rate limit requests based on various criteria. Combined with flow classifiers, the rate limiter can be used to implement sophisticated rate-limiting policies.
Aperture's Rate Limiter component relies on distributed caching to perform rate
limiting by storing information about the number of requests that have been made
by a particular client or service in the cache. This is made possible by the
peer-to-peer network that all Aperture Agents form. It also supports
lazy syncing
where agents will maintain a copy of the cache in memory, which can be used to
perform rate limiting without having to retrieve data from the cache. This
accelerates the rate-limiting process and reduces the load on the cache. The
Lazy sync feature can be enabled by setting the lazy_sync field to true in
the
Rate Limiter Component
configuration.
Using Aperture to Rate Limit GraphQL Queries
In this section, we will examine how Aperture can be used to rate limit GraphQL
queries. We will use a GraphQL application that implements a simple todo list
application. The code can be found
here.
Policy
We will use a policy that will rate limit unique users based on user_id Flow
Label.
Follow along with the GraphQL Query Rate Limiting Use Case to generate and apply the policy used in this blog post.
# yaml-language-server: $schema=../../../../../../blueprints/rate-limiting/base/gen/definitions.json
apiVersion: fluxninja.com/v1alpha1
kind: Policy
metadata:
labels:
fluxninja.com/validate: "true"
name: graphql-rate-limiting
spec:
circuit:
components:
- flow_control:
rate_limiter:
in_ports:
bucket_capacity:
constant_signal:
value: 40
fill_amount:
constant_signal:
value: 2
parameters:
interval: 1s
label_key: user_id
selectors:
- control_point: ingress
service: todo-service.svc.cluster.local
evaluation_interval: 1s
resources:
flow_control:
classifiers:
- rego:
labels:
user_id:
telemetry: true
module: |
package graphql_example
import future.keywords.if
query_ast := graphql.parse_query(input.parsed_body.query)
claims := payload if {
io.jwt.verify_hs256(bearer_token, "secret")
[_, payload, _] := io.jwt.decode(bearer_token)
}
bearer_token := t if {
v := input.attributes.request.http.headers.authorization
startswith(v, "Bearer ")
t := substring(v, count("Bearer "), -1)
}
queryIsCreateTodo if {
some operation
walk(query_ast, [_, operation])
operation.Name == "createTodo"
count(operation.SelectionSet) > 0
some selection
walk(operation.SelectionSet, [_, selection])
selection.Name == "createTodo"
}
user_id := u if {
queryIsCreateTodo
u := claims.userID
}
selectors:
- control_point: ingress
service: todo-service.svc.cluster.local
Rego focuses on providing powerful support for referencing nested documents and ensuring that queries are correct and unambiguous. Without diving deep into how Rego works, the source section mentioned in the above policy does the following:
- Parse the query
- Check if the mutation query is
createTodo - Verify the JWT token with a highly secretive secret key
secret(only for demonstration purposes) - Decode the JWT token and extract the
userIDfrom the claims - Assign the value of
userIDto the exported variableuserIDin Rego source
From there on, the classifier rule assigns the value of the exported variable
userID in Rego source to user_id flow label, effectively creating a label
user_id:1. This label is used by the Rate Limiter component in the policy to
limit the createTodo mutation query to 10 requests/second for each userID.
You can read more about how Classifiers extract Flow Labels from different sources here.
Demo Setup
To showcase the above policy in action, we will use the Aperture
Playground.
The playground comes pre-configured to run a k6 based
wavepool generator and a GraphQL application. The GraphQL application is a
simple To-Do application that allows users to create, update, delete and list
To-Do's and is deployed in the demoapp namespace. The playground includes
Aperture Agent
installed as DaemonSet
and the GraphQL application comes ready with Envoy sidecar proxy, configured to
communicate with Aperture Agent. You can read more about it
here.
Optionally, you can intercept your GraphQL queries using
Aperture SDKs.

The traffic generator is equipped with the ability to generate GraphQL requests
with JWT tokens as Authorization header. The GraphQL application is configured
to read the Authorization header, extract the JWT token and verify it using a
secret key. The JWT token is then decoded and the userID is extracted from the
claims.
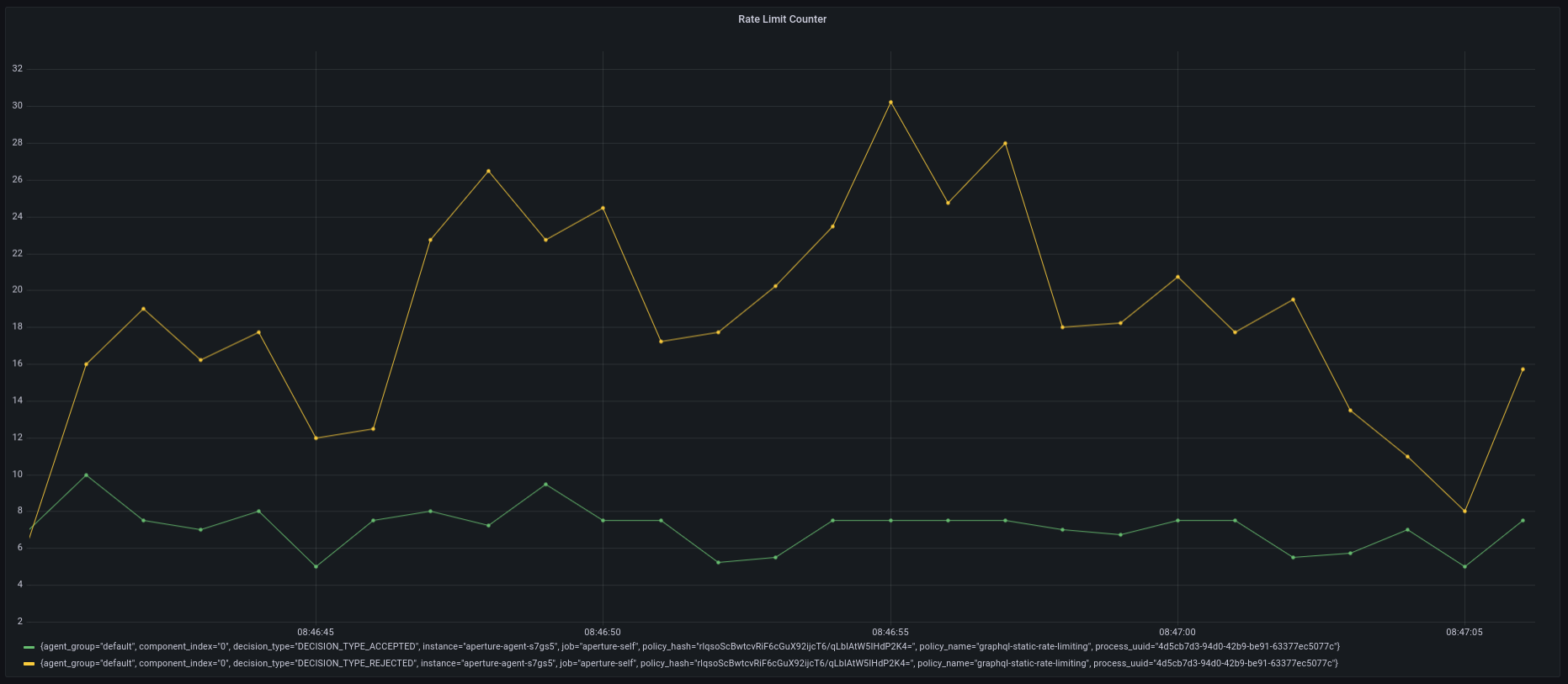
The traffic generator for this example is configured to generate 50 requests/second for 2 minutes. The policy allows no more than 10 requests per second.
Conclusion
In this blog post, we learned how FluxNinja Aperture can be used to rate limit GraphQL queries on a per-user basis and how it can be used to extract Flow Labels using Rego Rules. If you are looking for another interesting read, check out Why Adaptive Rate Limiting is a Game-Changer.
We invite you to sign up for Aperture Cloud, offering Aperture as a service with robust traffic analytics, alerts, and policy management. To learn more about Aperture open source, visit our GitHub repository and documentation site. Join our vibrant Discord community to discuss best practices, ask questions, and engage in insightful discussions with like-minded individuals.