
We’ve been hearing about rate limiting quite a lot these days, being implemented throughout popular services like Twitter and Reddit. Companies are finding it more and more important to control the abuse of services and keep costs under control.
Before I started working as a developer advocate, I built quite a few things, including integrations and services that catered to specific business needs. One thing that was common while building integrations was the need to be aware of rate limits when making calls to third-party services. It’s worth making sure my integration doesn't abuse the third-party service API. On the other hand, third-party services also implement their own rate-limiting rules at the edge to prevent being overwhelmed. But how does all this actually work? How do we set this up? What are the benefits of rate limiting? We’ll cover these topics, and then move on to the reasons why adaptive rate limiting is necessary.
How Rate Limiting Works
Purchasing concert tickets online can be a race against time. As tickets become available, your fingers frantically tap the 'buy' button, striving to secure your spot. Then, an error message appears, halting your purchase. Is the website malfunctioning, or did your rapid clicks trigger an unseen mechanism? This is a typical scenario where rate limiting might come into play. But what is this 'rate limiting' exactly?
Imagine you're at a café, trying to order a dozen different drinks all at once. The barista can only whip up so many cups at a time. If you keep asking for more, faster than the barista can make them, things are bound to get chaotic. That's where rate-limiting steps in. It's like the café manager setting a rule that says you can only order a certain number of drinks per hour. This way, the barista can manage the workload without spilling the coffee, and everyone gets their drink without a hitch.
In technical terms, your server is the barista, and the drinks are the requests. Too many requests at once and the server gets overwhelmed, affecting its performance. Rate limiting is the rule that sets how many requests a user, or a client, can make in a certain period. This prevents any single user from overloading the server, making sure the system remains smooth and stable.
But what happens when you hit the limit? Well, just like the café manager would tell you to wait before you order more, the server will tell you that you've hit your limit and to try again later. In the tech world, it often means receiving a message saying something like "429 Too Many Requests."
How to implement a rate limiter
Rate Limiters are implemented generally at the application level using one of the following algorithms
- Token Bucket: Requests consume tokens from the bucket, which refills at a consistent rate. If the bucket runs out of tokens, the request is rejected. This method can accommodate brief surges in request rates that exceed the bucket's refill rate.
- Leaky Bucket: Incoming requests are queued in the bucket. Tokens are steadily drained (or "leaked") at a fixed rate as the server processes requests. If the bucket reaches capacity, new requests are rejected. Unlike the token bucket, this approach ensures the request rate never surpasses the leak rate, preventing sudden bursts.
- Fixed Window: Limits the total requests within specific time intervals.
- Sliding Window: Allows a certain number of requests over a continuously shifting time frame, providing more fluid control compared to the fixed window technique.
You can read more about these algorithms here.
Limitations of Traditional Rate Limiting
Rate limiting helps in various ways, but there are certain limitations to it.
Static Rate Limiting
Static refers to a fixed rate limit for all users, which can be quite tricky to determine without thoroughly examining the platform usage at the individual user level. Still, it's not as simple as just picking a random number to indicate when the system should start rejecting or displaying a rate limiting message for additional requests.

We recently saw a situation like this when Elon Musk decided to set the limit too low, and a lot of things started breaking down. It wasn't just that, users began shifting from Twitter to alternative platforms like BlueSky, which provides better rate limiting for individual users.
Implementing a distributed rate limiter is hard, but deciding the right rate limit is even harder.
Overlooking the System State
A traditional rate limiter doesn't account for the stress on the system. As a consequence, there can be cascading failure if the rate limit is fixed and stress on the system keeps increasing. Conversely, resources may be underutilized when the rate limit is set so low that it doesn't allow for more usage. During such incidents, the rate limiting meant for protection can turn into a performance and user experience bottleneck.
The traditional rate limit just rejects a sudden surge of requests without considering the system's current state or its capacity to handle them. It would be more effective if the rate limit could be adjusted based on the system's usage, whether it is facing high usage or overload conditions.
Ignoring Context
Typically, many rate-limiting solutions are implemented based on IP addresses, which might not be sufficient to do rate-limiting. Traditional rate limiters don’t take any context of the request into account, treating all requests the same, irrespective of the nature of the request, its urgency, or its priority.
In such situations, a more advanced rate limiting system might be necessary. For
instance, if the service offers different plans such as premium, gold, silver,
or free, it can customize the user experience based on the chosen plan.
A similar approach can be seen in Twitter's recent rate limits based on user plan, i.e. verified user, unverified user, and new unverified user.
Edge-level Rate Limiting
It is implemented right at the network's edge, closest to the user. This helps manage the flow of requests being sent to the origin servers. However, Edge-level rate limiting alone is insufficient. It is also important to implement rate limiting within individual services to prevent potential overload or cascading failure. Using it between the services can prevent all kinds of cascading failure scenarios, but to achieve it you also need to take care of exponential backoff if you’re doing service-to-service rate limiting. Without this, the services themselves could unintentionally cause a denial-of-service (DoS) attack.
Exponential backoff allows your service or resource to wait for a certain period if the earlier request was rejected with 429 status, i.e. too many requests, and that period can keep on increasing exponentially if the requests keep getting slapped with that 429. It's like telling your service, "Hey, slow down buddy, it's getting crowded here. Let's try again after a while."
What is Adaptive Rate Limiting?
In contrast to a traditional rate limiter, an adaptive rate limiter takes infrastructure health into account. This ensures the right limit is in place to prevent the server from cascading failure scenarios and keeps it running even when resources are scarce. Later, with the help of auto-scaling, additional resources can be added as needed.
Returning to the topic of customer plans; request priorities could be configured in a way that your premium users have much more relaxed rate limits compared to free users. All these configurations can be tailored to your business use case, but this gives you an idea of the benefits it could provide. In the case of service-to-service rate limiting, maintaining requests per sec (RPS) between services becomes easier.
To gain a better understanding of adaptive rate limiting, let's picture ourselves in a bustling café. Traditional rate limiting can be compared to a barista who strictly serves a fixed number of customers every hour, let's say a hundred customers. It doesn't matter if they are loyal regulars or first-time visitors; the barista adheres to the predefined limit.
Now, let's introduce adaptive rate limiting, our savvy barista. This barista carefully surveys the café, identifying the familiar guests, the esteemed VIPs, and the new faces. They might prioritize serving the VIPs and slow down the pace when there is an influx of newcomers. The goal is to adapt and avoid a one-size-fits-all approach, ensuring everyone has a delightful café experience and the place is not overcrowded.
And that's the essence of adaptive rate limiting. It's about being intelligent, flexible, and ensuring smooth operations.
Benefits
Rate limiting offers several benefits beyond handling overload situations. Here are some key advantages to consider:
- Cost reduction: It helps in dealing with sudden spikes of requests, reducing server costs by efficiently managing resource utilization.
- Resource fairness: from prioritization to equal fairness of resource distribution, ensuring no user is monopolizing the resources.
- Prevention of server abuse: As we journey into the Artificial Intelligence (AI) era, numerous companies aim to train expansive Language Learning Models (LLMs). To achieve this, they must scrape or crawl a substantial amount of data from websites. Undoubtedly, such scraping activities will exert resource demands on the infrastructure of website owners. Without proper limitations or prevention mechanisms in place, the companies being scraped could find themselves bearing the financial burden for the usage of infrastructure that generates no value for them. This could also lead to server resource abuse and consequent performance degradation, as the resource usage could exceed the capacity of their infrastructure.
- Website functionality: Maintain optimal website functionality, even during periods of high user traffic such as the Reddit hug of death, HackerNews influx, viral marketing campaigns, or potential DDoS attacks.
So, if you find yourself in the spotlight or face any of these scenarios, rate limiting can play a crucial role in supporting your website's performance. Please let us know if any of these situations resonate with you! ;)
Adaptive Rate Limiting in Action
Using adaptive rate limiting, we were able to protect PostgreSQL instances running in Aperture Cloud infrastructure from sudden surges of traffic, ensuring the high priorities requests are respected & bad actors are penalized. You can read more details in this blog "Protecting PostgreSQL with Adaptive Rate Limiting.”
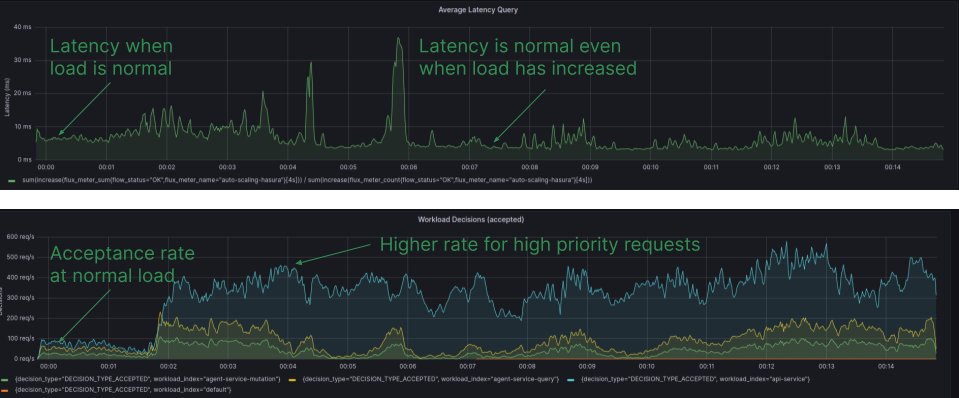
Grafana Dashboard, displaying the latency and workload acceptance rate for individual workloads with Aperture policies implemented. Latency remains within the desired range, and the acceptance rate remains high, even during periods of high load.
What's Next?
In this post, we aimed to cover the what and why of adaptive rate limiting - how it works and why it's needed. In a future post, we'll dive into how to implement adaptive rate limiting using FluxNinja Aperture.
We hope you understand how rate limiting works, why adaptive rate limiting is needed, and perhaps even think about it when you visit the café. It's the next big thing, and we're the experts on that at FluxNinja. We invite you to explore various Use Cases in action and share your thoughts, so we can keep improving this solution for you. Join our vibrant Discord community to discuss best practices, ask questions, and engage in insightful discussions with like-minded individuals.
For further reading on Adaptive Rate Limiting and related topics, we recommend exploring the following resources