
Graceful degradation and managing failures in complex microservices are critical topics in modern application architecture. Failures are inevitable and can cause chaos and disruption. However, prioritized load shedding can help preserve critical user experiences and keep services healthy and responsive. This approach can prevent cascading failures and allow for critical services to remain functional, even when resources are scarce.
To help navigate this complex topic, Tanveer Gill, the CTO of FluxNinja, got the opportunity to present at Chaos Carnival 2023 (March 15-16), which happened virtually, the sessions were pre-recorded. Though, attendees could interact with speakers since they were present all the time during the session.

Chaos Carnival 2023 is a global two-day virtual conference for All Things Chaos Engineering. It offers more than just a standard conference experience, providing a unique opportunity to bring together the most skilled and enthusiastic chaos engineering experts on one platform to exchange ideas on Chaos Engineering and Kubernetes.
The conference focused on chaos engineering and covered various topics related to it. During the talk, we discussed several key underlying topics, including:
- Why is failure inevitable, and how can we sustain ourselves during it?
- What are Concurrency Limits and Little's Law?
- How can Concurrency Limits help protect services from overload?
- Real-world case studies of implementing Concurrency Limiting in Microservices
- Challenges in implementing Concurrency Limiting in Microservices
- What is Prioritized Load Shedding, and what are its benefits?
- The need for a unified observability and controllability platform for cloud-native applications
- How Aperture enables intelligent load management?
If you missed the live talk, don't worry; we have a recorded version available here.
Why is failure inevitable? And how to sustain within it?
The talk began by exploring the dynamics of how a service gets overwhelmed, and its impact on the system.
Microservices' architectures, because of the sheer number of components and dependencies involved, are inherently vulnerable to cascading failures.
Additionally, the dynamic nature of microservices architecture and the frequent updates and changes to the components increase the likelihood of failures. Other factors that can contribute to failures include unexpected traffic spikes, service upgrades with performance regression, upstream services or third-party dependencies slowing down, and retries.
Failures are inevitable in such systems and can cause chaos, disruption, and poor user experiences. Managing failures and ensuring seamless user experiences becomes a critical challenge here. To sustain within it, we need to prioritize which workloads or users receive resources during a degraded state,
In the below presentation, we explored a scenario when a service becomes overwhelmed, and requests start to back up, leading to increased response time and eventually, timeouts;
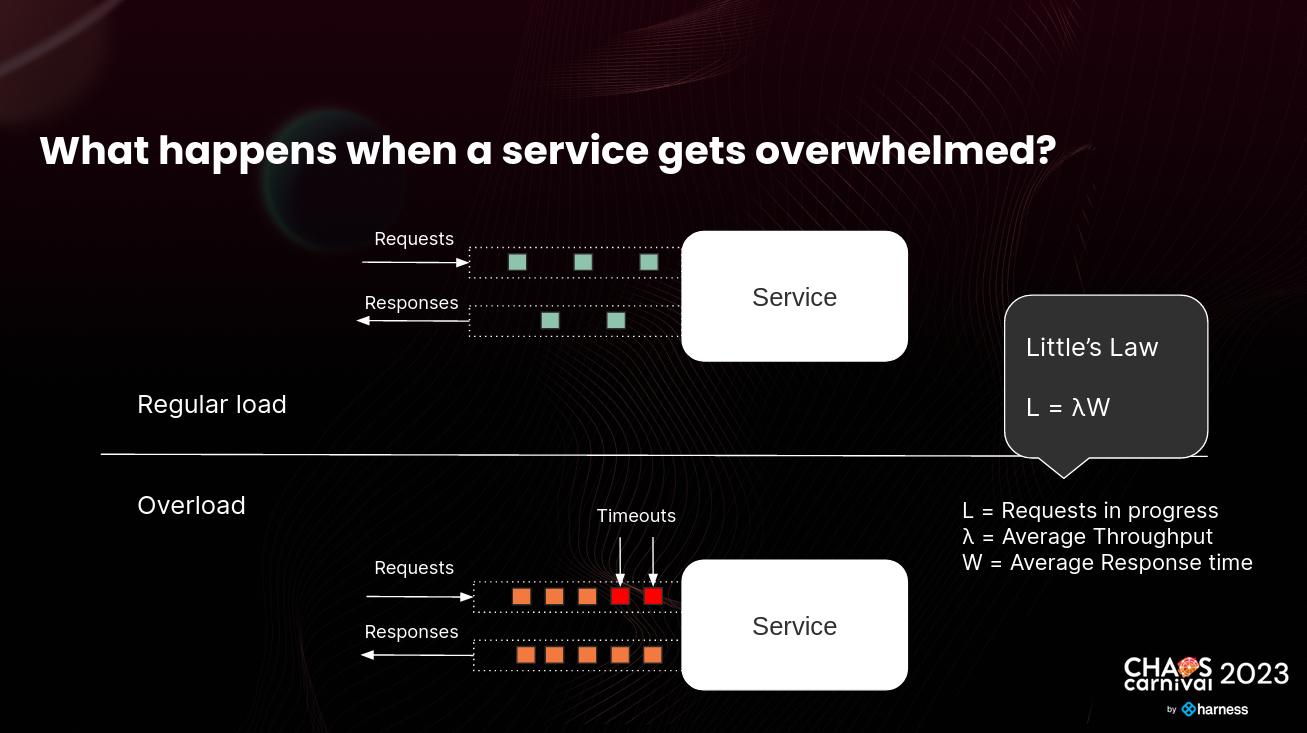
What exactly is the concurrency limit? How Little’s law helps?
Once we understood how service gets overwhelmed, we looked at the concurrency limit of service to solve this problem. Tanveer described a concurrency limit as the maximum number of requests a service can process in parallel before response time starts to deteriorate. Thanks to Little's law, we can also determine the maximum average throughput a service can handle before becoming overwhelmed.
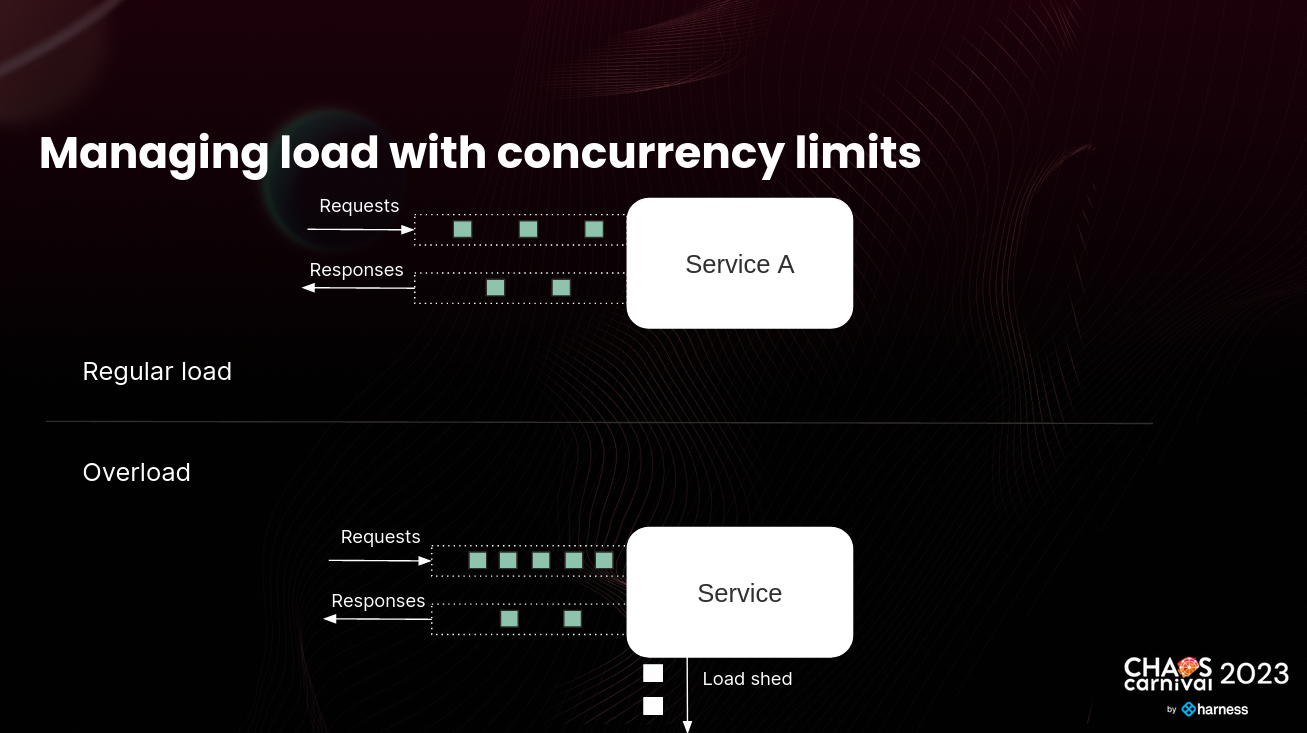
How Concurrency Limits Help Protect Services from Overload
As we continued our discussion, we discussed the benefits of setting a concurrency limit. This limit protects services from overload by placing a maximum on the number of in-flight requests that a service can handle. By doing so, it preserves performance and availability for users, even during high traffic periods.
Real-World Case Studies
The talk also examined real-world case studies to better understand the impact of concurrency limits on microservices. For example, the Pokémon Go app experienced a load balancing issue that resulted in slow performance and many error responses due to the lack of protective techniques like concurrency limits and prioritized load shedding. This case study demonstrates the importance of implementing concurrency limits in a dynamic microservices' environment.
Challenges with Implementing Concurrency Limits
However, implementing concurrency limits in a constantly changing microservices environment poses several challenges, including:
- Determining the ideal maximum number of concurrency requests.
- Difficulty in determining the ideal value in a constantly changing microservice environment.
- Monitoring and adjusting concurrency limits.
- Coordinating concurrency limits across multiple services.
- Visibility into the state of the system.
Protective Techniques for Load Management
We discussed how prioritized load shedding helps in preventing load-related failures and preserving critical user experiences. This approach allows for the shedding of lower priority workloads during a degraded state, ensuring that critical services remain functional even when resources are scarce. Prioritized load shedding prevents cascading failures, preserves performance and availability for critical services, and allows for a smooth-running system even during high traffic.
Need for a Unified Observability and Controllability Platform for Cloud Native Applications
A comprehensive and scalable load management solution is needed to provide real-time visibility into the state of the system and the effectiveness of concurrency limits. This solution should be able to automate the process of setting, monitoring, and adjusting concurrency limits in real time to overcome these challenges. To achieve this, we need a unified observability and controllability platform for cloud native applications. This platform should be able to classify and prioritize requests in a service-independent and generalized way, as well as automatically estimate the cost of admitting various types of requests. Solving these challenges will help optimize the performance of our services and provide better services to our users.
How Aperture Enables Intelligent Load Management?
During the talk, Tanveer explained the details of how Aperture works. For more information, you can refer to the recorded talk. At a high level, Aperture addresses the challenges of implementing concurrency limits in microservices. As an intelligent load management platform, it optimizes the performance of the system.
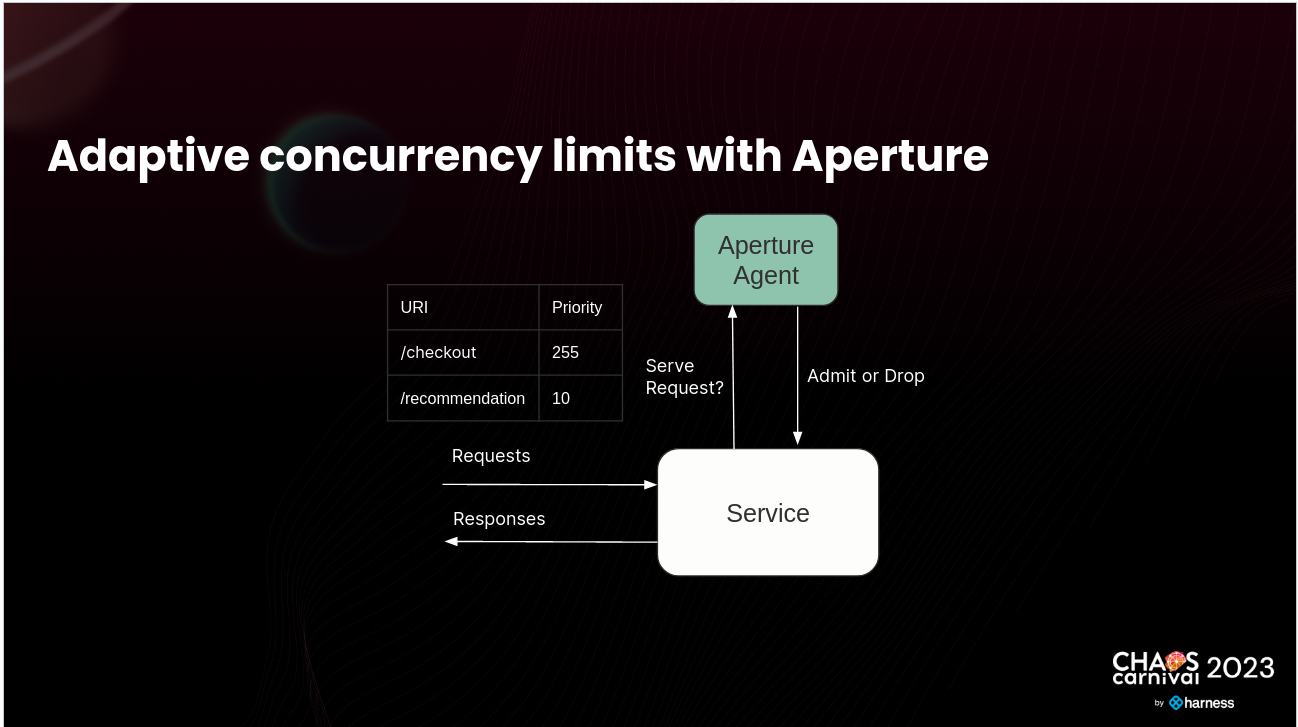
Some benefits of using Aperture include:
- A comprehensive and scalable load management solution
- A distributed architecture that uses Prometheus and etcd databases for telemetry and configuration data
- The ability to prioritize workloads based on their attributes and importance
- Direct benefits of Aperture out of the box include dynamic concurrency limits, circuit-based policies, distributed rate limiting, and auto-scaling
- Real-time insights and analytics
Load Management Strategy
Load management techniques can be categorized along a spectrum of proactive to reactive approaches. At the proactive end of the spectrum are preventive techniques, such as rate limiting, which aim to prevent issues from arising by limiting the impact of heavy users. Moving along the spectrum, protective techniques like adaptive concurrency limits and prioritized load shedding are designed to minimize the impact of service outages or degradation events, ensuring that services remain available, and customer experience is maintained.
By implementing a combination of these techniques, we can create a complete load management strategy that can adapt to changing workloads and dependencies while ensuring high availability, scalability, and reliability of cloud-native applications. However, to be effective, these strategies require centralized awareness and coordination.
That’s what Aperture is — A comprehensive and scalable load management solution that enables intelligent load management.
Its load management strategy prioritizes workloads based on their attributes and importance, allowing for critical services to remain functional even when resources are scarce.

In conclusion, this talk is a must-attend for anyone interested in understanding the importance of managing failures in complex microservices architectures. The insights and tips shared in the presentation will help attendees understand the dynamics of overload in a single service, the benefits and challenges of implementing concurrency limits, and the tools needed for a smooth-running system.
If you missed the Chaos Carnival Conference, this recap is a great way to catch up on all the exciting highlights. We have a recorded talk available here if you want to dive deeper into the topic. Join our vibrant Discord community to discuss best practices, ask questions, and engage in insightful discussions with like-minded individuals.