
As we enter 2024, Generative AI-based applications are poised to become mainstream
Given Generative AI’s limitations at the start of 2023, the world was skeptical whether Generative AI would deliver tangible value to the businesses and to the customers. With the current state of Generative AI services, it seems totally possible. Many of us have by now built some prototypes of Generative AI-based apps that are effectively solving specific business problems and delivering concrete value to a small set of users.
This was possible due to continuous improvements in Generative AI services from GPT-3.5 to GPT-4-Turbo, from LlaMa to Mistral, and many more incremental as well as disruptive developments. We were able to confidently use Generative AI services to deliver value consistently, and the dream of building useful Generative AI-based apps is not a dream anymore but a reality.
In 2024, we will see massive adoption of such Generative AI-based products
After building a prototype, the next challenge one needs to solve is how to ship those prototypes to the hands of millions of such users reliably in production. And that is not yet done by many but has been proven to be possible.
A prime example of this is CodeRabbit, a leading AI Code Review tool that utilizes GPT for automating PR reviews.
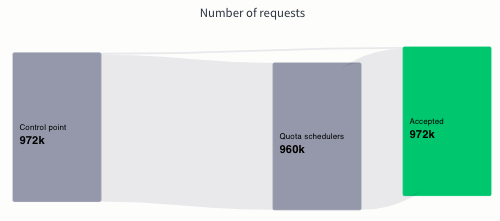
CodeRabbit was launched in Sep 2023, and has already scaled to 1 million+ monthly requests served using GPT APIs. Its 100% success in delivering those requests and a satisfied customer base of 57000+ code repositories demonstrates the practical viability of Generative AI in building scalable businesses that deliver concrete value to users.
Transitioning from a prototype to a production stage is not as easy though, it involves several challenges. These include managing operational costs, preventing service abuse, handling AI service outages, and maintaining a robust user experience while scaling to accommodate millions of users. CodeRabbit's journey exemplifies that with the right approach, these challenges can be overcome to achieve success in production.
This article aims to guide you through the process of transitioning your Generative AI-based application from prototype to production. We will discuss strategies to address the common hurdles such as cost efficiency, reliability, scalability, and user experience optimization. The goal of this article is to provide a clear, technical roadmap for scaling your Generative AI application effectively.
Understanding foundational Generative AI models and services
There are multiple foundational Generative AI models and services encompassing a wide range of technologies that have the capability to generate new content, solve problems, or process information in innovative ways. These services can be utilized to enable more specific use cases.
These Generative AI models/services can be broadly categorized as follows:
Text generation and processing
Leading models to generate or process text are - GPT-4, Mistral, Claude, LlaMa, and so on. They can generate human-like text, answer questions, summarize content, translate languages, and more. Most of these models are also available as API service, so it is easier to implement those without worrying about the model deployment. But you have to do all other things related to productizing the solutions built on top of these services.
Example use cases:
- Automated Writing Assistants for Grammar checking, style improvement, and content generation, and so on.(such as Grammarly or ProWritingAid)
- Automatically generate draft blog posts and articles
- Create conversational dialogue for chatbots and virtual assistants
- Generate ideas and creative story premises for writers
- Summarize texts and documents for consumers
Image generation
Image Generation models such as MidJourney, Stable Diffusion, DALL-E, Imagen, Imagen Editor etc. can create images and artworks from textual descriptions.
Example use cases:
- Generate unique profile pictures and avatars
- Create original artwork for digital artists and designers
- Produce images for marketing materials and social media posts
- Conceptualize product designs through visualizations
Voice generation
There are multiple high-quality Text-to-Speech (TTS) models and services available now that convert text into spoken voice, such as ElevanLabs, XTTS/Coqui, WaveNet, Amazon Polly, etc.
Music or Sound generation
Some of the popular music or sound generation models/service include MusicGen, AudioGen,
AudioCraft, Jukebox, Magenta, WaveNet, etc.
Example use cases:
- Compose background music for videos and other multimedia
- Create custom ringtones and notification sounds
- Produce sound effects for games, VR, and AR experiences
- Generate musical ideas and samples for musicians
Video generation
This category is not as mature as other Generative AI categories and we might have to wait a bit more for improvements to see massive amounts of practical use cases. Presently, some of the popular models/services to generate video from text/image are - RunwayML, CogVideo, Imagen, Make-a-Video, Phenaki, Synthesia, Stable Video, VideoPoet, and so on.
Example use cases:
- Automatically produce training videos for educational purposes
- Create visual marketing content to promote brands and offerings
- Generate video templates and effects for editing
- Conceptualize scene frameworks for filmmakers and creators
General purpose
Reinforcement learning models - can be optimized to complete various sequential decision-making tasks like game playing, autonomous robotics vehicle operations. Some examples in this category are - NVIDIA DRIVE (self-driving solutions) AlphaZero (chess game playing).
Example use cases:
- Play games against humans by mastering gameplay strategy
- Control robotic systems to automate business processes
- Optimize machine behaviors for complex sequential tasks
- Develop product innovations through iterative simulated testing
Future categories
In 2024, we might see some more categories as more foundational models are created that are optimized for a specific task or industry and enabling more use cases. Some of the new categories we predict to get developed in 2024 will be related to data analysis, predictions, gaming, industrial automation, autonomous vehicles, healthcare diagnostic, adaptive learning, and explainable AI (XAI).
You or your competitors might have built a prototype based on these foundational models or services already. If not, it is likely that you’ll do that in 2024. However, how do you move beyond the prototype and make it available in production to real users, and that too at a practical scale which drives significant impact?
Path from prototype to production
Drawing on my personal experience and the insights gained from others, let me share the specific steps to take your Generative AI-based solution from prototype to production. I'll also provide tips for each step to take specific actions in your journey to productionize your Generative AI-based application.
1. Choose the right Generative AI model or service for the task
Start with the basic understanding of various models that you can use and how they fit your requirements. The earlier section might have provided you a high-level overview. To move to the next step of choosing the right model or service, explore some of the popular comparison/benchmarks for Generative AI models such as:
- Chatbot Arena Leaderboard provides comparison of various LLMs based on various benchmarks. Their official website provides more utilities for comparison.
- Open LLM Leaderboard provides comparison of Open Source LLMs based on various benchmarks.
While these general benchmarks can help with high level filtering of the models/services you might want to use, one must test these models against their full application requirements using a large enough sample to prove production readiness. Assess accuracy, relevance, runtime, and other performance metrics for your use case.
2. Manage prompt engineering effectively
To effectively use a Generative AI model/service, you need to provide and iterate on prompts. Your service quality depends on it. Which is why managing your prompts for the AI services is crucial in production. Following techniques can help
- Curate a library of tested base prompts - Start by gathering prompts used during prototyping that yield high quality, relevant outputs in your domain. These can serve as standard building blocks.
- Log all prompts and iterations - Track all prompts and model versions in your production systems, along with key metric scores. Analyze for continuous refinement.
- Implement prompt templating conventions - Structure prompts into clear components like task framing, content constraints, tone/style parameters, etc. to simplify iteration.
- Build a prompt enrichment pipeline - Augment prompts with external data like lexicons, knowledge bases, and human feedback to improve them over time.
- Control variations with conditional parameters - For user personalization or experimentation, rely more on conditional tuning of style, length, etc. rather than fully custom prompts.
- Allow spaces for innovation - Leave room within composable prompt templates to keep introducing and testing new creative variants.
3. Monitor quality and mitigate hallucinations
Once you see that your solution is working on your local or for some users, you must not stop there, you still need to think about quality control via monitoring and specifically to manage hallucinations. Some of the following techniques can help.
- Automate testing process to identify issues early - You can use LLM as an evaluation tool to automate some of the tasks in the testing process. Run those tests before releasing the new version to customers.
- Set up monitoring for model drift - As data patterns/distributions shift over time, monitor drops in prompt effectiveness and update appropriately.
- Check outputs for consistency - Spot check generations directly for coherence, factuality, toxicity to catch model performance regressions requiring prompt tuning.
- Controlled beta access - We recommend releasing controlled beta access to test the product quality and identify hallucinations. It ensures the application hits quality requirements, establishes a clear user agreement, and protects key reputation aspects during closed beta with selective users.
- Human review as the last defending line - You should also have a human review step for some of the different test cases before deploying the release to customers.
4. Wrap as a production API/service
Expose core functionality via REST or other APIs for easy integration into the application front-end. Add input validation, authentication, monitoring, etc.
5. Establish scalable infrastructure
Standard generative models have significant system resource demands. Even when you’re using the services which are taking care of those scalable infrastructure needs (e.g. GPT API), the number of requests you’ll be sending to those services will be quite high and that will require you to think about your infrastructure. Assess expected request loads and build a distributed cloud infrastructure for cost-efficient scalability. You will likely need to containerize using Docker/Kubernetes and set up auto-scaling.
6. Setup rate limiting for cost optimization and service abuse protection
When it comes to load management, the requirements for Generative AI-based applications are way higher than your usual systems. The amount of service load is humongous as your system is talking to an external Generative AI service at a frequency which your normal app usually wouldn't need. You and your customers will frequently find dealing with errors such as “429 - Too many requests” and CPU usage going close to 100%. Avoiding these issues and the requirement of low latency is critical to retain your customers.
It is not easy, and making your application accessible from a service availability or cost perspective is fundamental to grow adoption for your product. If you use the right tools, rate limiting and caching can be easy pickings in ensuring your service does not go out of service or becomes unsustainably expensive to manage.
Tools such as FluxNinja Aperture can be helpful, which are purposefully designed to protect Generative AI-based applications from abuse and high cost.

As shown in the above architecture diagram, FluxNinja Aperture or your own custom solution for rate limiting needs to sit in between your app’s backend and Generative AI service to takes care of:
- Rate limiting request based on the quota for your Generative AI service
- Queuing requests to avoid overwhelming your system or the external Generative AI service system you use
- Prioritizing requests based on user tiers
- Caching requests to reduce external AI service costs and deliver results to user faster
- Monitor your service health and how you’re interacting with the external AI service
Using FluxNinja, all these steps can be done with a simple sdk integration of FluxNinja in your code. It can provide you protection from abuse as well as control your costs.

In the end, this step will result in a better user experience and boost your app’s growth.
Treat these 6 steps as a checklist for going from prototype to production. Appreciate your thoughts and tips to make this checklist even better.
Conclusion
The Generative AI-based application market is growing exponentially. There is an opportunity to use this to grow and stay ahead of your competition. Although it is not an easy task to take your Generative AI-based product from prototype to production, it is totally possible to achieve it, similar to how CodeRabbit built a cost-effective Generative AI-based app. And you can make it easier by approaching in the organized manner and utilizing the right tools, as we discussed in this article. Some of the key points to remember are - choose the appropriate model, manage prompts effectively, use testing techniques specific to Generative AI-based apps, implement rate limiting and caching.
P.S. This is a primer of our series “Generative AI Apps Prototype to Production Roadmap”. If you want to dig deeper into any of the points we mentioned in this article, check out our other articles in the series.