

A robust reliability automation strategy is essential for the successful management of cloud applications. It not only sets top-performing apps apart from the rest, but also establishes trust with end customers and drives business success. Whether you are a small or large organization, investing in reliability management is crucial for ensuring the availability, performance, and consistency of your services.
In this blog, we will introduce you to the fundamental principles of reliability automation, known as the Reliability Spectrum. Consist of three key pillars - prevention, protection, and escalation & recovery - the Reliability Spectrum provides a comprehensive framework for maintaining a reliable cloud application. Join us as we delve into the details of each pillar and explore the essential components of a successful reliability automation strategy.
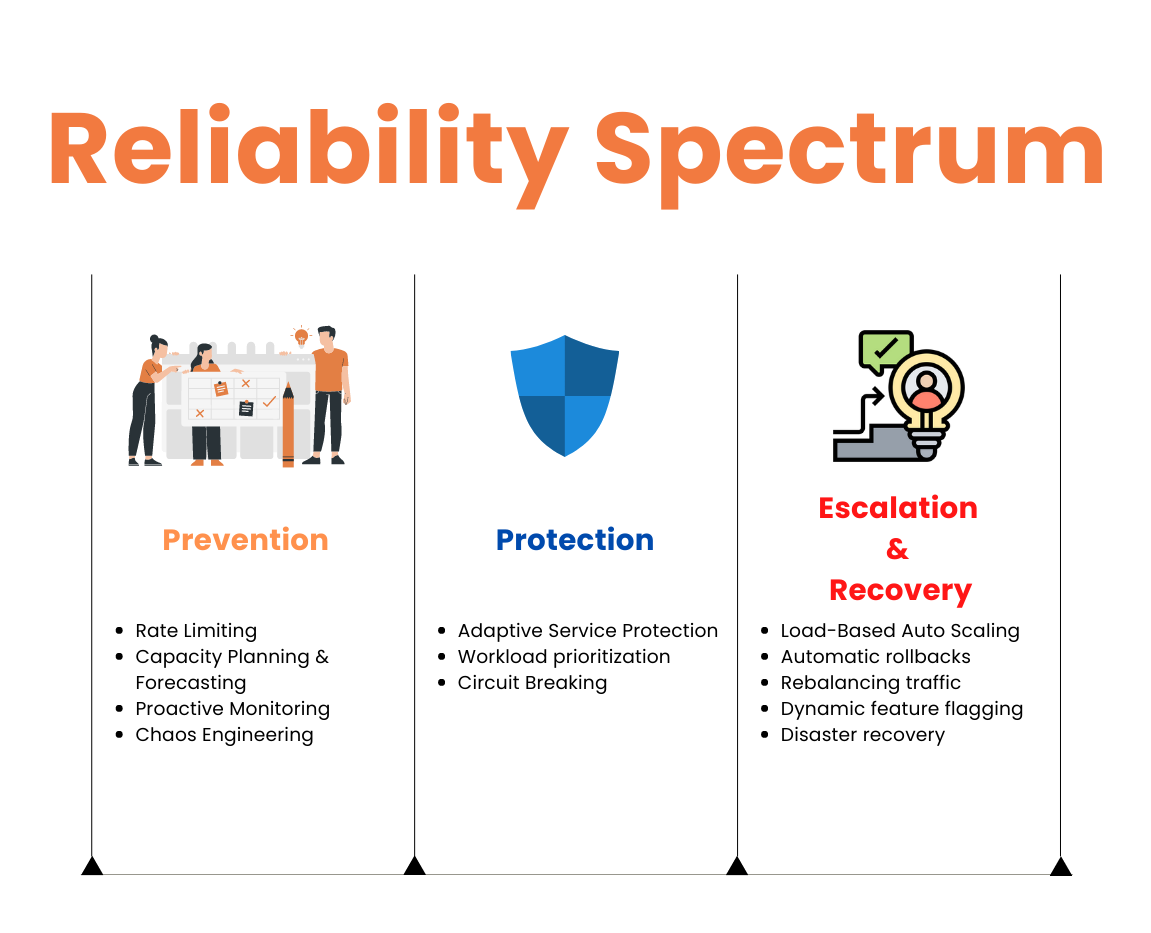
Prevention: To prevent issues from arising in the first place, the following techniques can be applied:
- Rate Limiting: To maintain service availability for all users, it's important to set limits on the number of requests per user or session. This technique is especially useful in preventing service degradation caused by misuse of resources, such as excessive requests made through scripts or bots. By implementing rate limits, you can ensure that service resources are not overburdened and are available to legitimate users. Additionally, rate limiting can prevent potential security risks associated with excessive requests and protect the service from abuse. Using open source Aperture, any service can be quickly augmented with Distributed Rate-Limiting functionality.
- Capacity Planning & Forecasting: Anticipating and preparing for future demands on your infrastructure is a crucial aspect of preventing application failures. Capacity planning involves anticipating and allocating the necessary resources and infrastructure to meet future demand. Forecasting is a technique used to predict future demand based on past trends and historical data, which can be used to drive informed decisions about auto-scaling and resource allocation. By effectively planning for and forecasting future demand, you can ensure that your infrastructure can meet the needs of your users, helping to prevent application failures and ensure high availability.
- Proactive Monitoring: Proactive monitoring is a key component of reliability and is focused on detecting and resolving issues before they become critical. The foundation of proactive monitoring is observability, which involves collecting data from various components of the service and using that data to monitor the health, performance, and behavior of the service. With observability in place, you can detect and resolve issues in real-time, ensuring the high availability and performance of your services. Additionally, observability provides valuable insights into how your services are functioning and being utilized, allowing you to make informed decisions about optimizing and improving your services. Proactive monitoring through observability is an essential step towards preventing disruptions and ensuring reliable services.
- Chaos Engineering: A proactive method of improving system reliability by intentionally introducing controlled chaos into the environment. Experiments are conducted to simulate real-world failures and observe how the system responds under stress. The results are then used to identify weaknesses and remediate them before they cause outages, thereby improving resilience and reducing downtime. Continuous learning from these experiments helps organizations proactively prevent system failures and enhance reliability.
By using a combination of these techniques, you can improve the reliability of your services and prevent issues from arising.
Protection: Despite taking preventive measures, incidents like outages or service degradation can still occur in a system. To mitigate the potential harm to customers and businesses, it's crucial to have a solid protection strategy in place that can quickly and effectively minimize the impact of these incidents. A well-designed protection strategy helps to ensure that services remain available, and customer experience is maintained during and after an outage or degradation event.
- Adaptive Service Protection: To ensure reliable and optimal performance of a service, adaptive service protection safeguards against both external traffic spikes and performance regression caused by bad deployments. This technique dynamically monitors response times and health of the service to detect overloads. If the limit is exceeded, the system automatically reduces the load, balancing good throughput with its ability to handle excess requests. Confidently maintain your service's reliability and performance by dynamically monitoring response times and system health to detect and manage overloads.
- Workload Prioritization: During high-demand periods, this technique prioritizes certain workloads or user types to manage the load on the system. Working in tandem with Adaptive Service Protection, which monitor response times and health to detect overloads, Workload Prioritization ensures critical requests are served first while maintaining a balance between user experience and system reliability. Aperture can quickly set up both Adaptive Service Protection and Workload Prioritization for your service.
- Circuit Breaking: A circuit breaker component is used to detect and prevent service failures in one part of the system from cascading to other parts of the system. The circuit breaker component acts as a switch that trips when a certain failure threshold is reached, such as a high number of failed requests or an extended response time. When the circuit breaker trips, incoming requests are either redirected to an alternative service or rejected, depending on the specific implementation. This helps to prevent the system from getting overwhelmed and reduces the risk of cascading failures. However, this can result in poor user experience as all requests are outright rejected. Alternative methods, such as Adaptive Service Protection, offer better protection without this drawback.
Escalation & Recovery: Prevention and protection strategies minimize outages and good throughput, but they do not adapt the service infrastructure or application logic to meet real-time demand or failures (for example, bad deploys or wider outages). Escalation & recovery strategies help quickly resolve issues, minimize downtime, and maintain service availability:
- Load Based Auto Scaling: Auto scaling is a strategy that balances resource utilization and user demand by dynamically adjusting the number of service instances. With Aperture, auto-scaling can be achieved through policies that consider both service health and load throttling. For example, a policy can be set to activate auto-scaling when service is throttled due to overload. This helps ensure efficient resource use and improved service availability for a more resilient architecture.
- Automatic Rollbacks: In case of a service degradation happen, automatic rollbacks allow you to revert to a previously stable version of your service, reducing downtime and minimizing the impact on your users.
- Traffic Rebalancing across Regions: This strategy helps ensure the availability of your services in case of a disaster, such as a data center outage, by redistributing traffic across multiple regions. By temporarily using excess capacity in one region to serve excess requests from another, you can increase resiliency, maintain low-latency service for your users, and improve overall reliability of your service.
- Dynamic Feature Flagging (Real-time Feature Flags): This technique allows you to turn off or toggle specific features during times of overload, preserving critical user experiences and reducing the impact of outages.
- Disaster Recovery: Disaster recovery ensures quick restoration of services and data during a major outage. This involves regularly backing up application data and testing the disaster recovery plan to ensure its effectiveness and efficiency. A robust disaster recovery plan reduces downtime, minimizes impact on customers, and instills confidence in the organization's ability to handle unexpected events.
In conclusion, the reliability of cloud applications is vital for success, and automation of reliability is the key to achieving it. By adopting a combination of prevention, protection, and escalation & recovery strategies, organizations can ensure that their services are consistently available, performant, and of high quality, making reliability a competitive edge in the market. By proactively identifying and mitigating potential failures and vulnerabilities, organizations can minimize downtime, improve resilience, and increase customer satisfaction, creating a stable and reliable foundation for growth and success.
We invite you to sign up for Aperture Cloud, offering Aperture as a service with robust traffic analytics, alerts, and policy management. Learn more about using Aperture open-source for reliability automation by visiting our GitHub repository and documentation site. Lastly, we welcome you to join our vibrant Discord community to discuss best practices, ask questions, and engage in insightful discussions with like-minded individuals.