
In the fast-evolving space of generative AI, OpenAI's models are the go-to choice for most companies for building AI-driven applications. But that may change soon as open-source models catch up by offering much better economics and data privacy through self-hosted models. One of the notable competitors in this sector is Mistral AI, a French startup, known for its innovative and lightweight models, such as the open-source Mistral 7B. Mistral has gained attention in the industry, particularly because their model is free to use and can be self-hosted. However, generative AI workloads are computationally expensive, and due to the limited supply of Graphics Processing Units (GPUs), scaling them up quickly is a complex challenge. Given the insatiable hunger for LLM APIs within organizations, there is a potential imbalance between demand and supply. One possible solution is to prioritize access to LLM APIs based on request criticality while ensuring fair access among users during peak usage. At the same time, it is important to ensure that the provisioned GPU infrastructure gets maximum utilization.
In this blog post, we will discuss how FluxNinja Aperture's Concurrency Scheduling and Request Prioritization features significantly reduce latency and ensure fairness, at no added cost, when executing generative AI workloads using the Mistral 7B Model. By improving performance and user experience, this integration is a game-changer for developers focusing on building cutting-edge AI applications.
Mistral 7B: The Open Source LLM from French Startup Mistral AI
This powerful model boasts 7 billion parameters and a sequence length of up to 8k, making it an efficient choice for tackling various tasks.
In the world of LLMs, Mistral 7B is renowned for its impressive performance, defeating its counterparts Llama 1 and 2 on numerous benchmarks. The open-source nature of this model has paved the way for a multitude of opportunities, enabling startups to offer cost-effective AI applications by running Mistral locally or offering LLMs as a service.
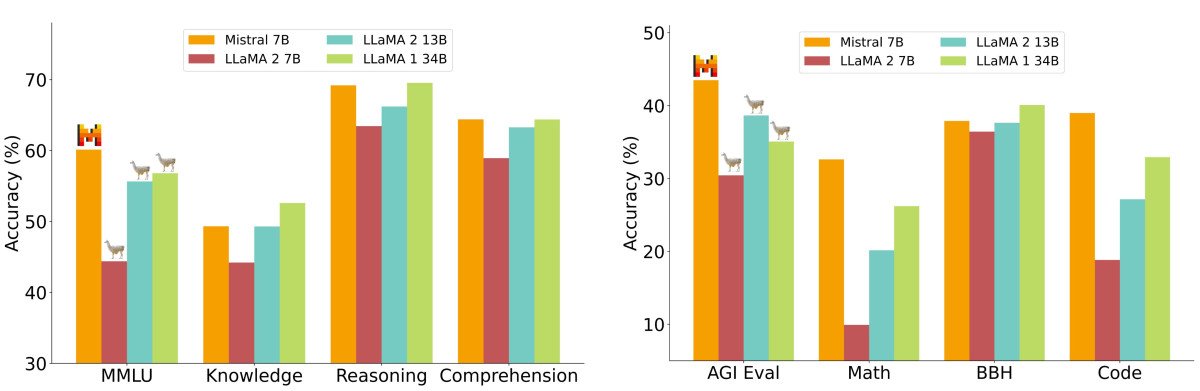
Mistral AI's decision to open-source Mistral 7B is a step towards leveling the playing field for smaller players in the competitive AI landscape. It not only empowers developers and businesses but also fosters collaboration and innovation within the industry.
Cost Problem: Self-Hosted Vs AI APIs Providers
The adoption of AI models like Mistral has become increasingly popular across industries, leading to various challenges associated with their deployment and usage. One such challenge is the cost of operating these models, whether through self-hosting or using API endpoints.
Self-hosted models and API Cloud-hosted commercial models each present distinct advantages and limitations when it comes to using AI models like Mistral. However, as demand for these models continues to surge, companies face growing challenges in maintaining optimal performance and user experience while keeping costs under control.
Opting for LLMs like OpenAI will relieve your team from operational burdens, but you'll still encounter strict rate limit quotas and the need to manage costs effectively with pay-as-you-go models that scale based on usage. This can be a challenge as usage might not always be predictable. Alternatively, self-hosting LLMs can save costs in the long run, but it requires building in-house expertise for deployment and operation. While you'll no longer have to worry about rate limits, you will need to manage saturated infrastructure that is neither cost-effective nor easy to scale instantly. To ensure priority access across workloads and fairness among users of your service, some form of control is necessary. The high demand for AI resources and the associated costs pose a significant challenge for businesses. Companies must balance the need for cost savings against ensuring uninterrupted access to these essential tools.
FluxNinja Aperture is a purpose-built solution for streamlining the consumption of LLMs. It offers the ability to implement rate limits to ensure fair access across users for any workload. For self-hosted models, it can enforce concurrency limits and provide fair and prioritized access across workloads and users.
Testing Mistral with Concurrent User Access
We used Ollama to quickly install a local Mistral instance on our machine and send prompts to their endpoint. To simulate real-world conditions, we performed the following steps:
- Compiled a set of 25 diverse prompts for both open-source and paid users, which included coding challenges, sales pitches, legal questions, content generation, etc.
- Developed a Typescript Application to manage both scripts and return responses from the generated answers.
- Implemented a script to run the application concurrently for both user types based on a predefined number of users.
In our initial test run, we operated with only 2 concurrent users (1 open source and 1 paid), thus sending 50 prompts in total. We noticed that Mistral demonstrated impressive effectiveness, delivering answers within the range of 10-30 seconds based on the prompt context.
For the subsequent test, we increased the number of simultaneous users to 10 (5 per tier), resulting in a total of 250 prompts being processed. Initially, responses were generated swiftly; however, after handling a few queries, we began experiencing noticeable delays, with wait times escalating up to 5 minutes and beyond.
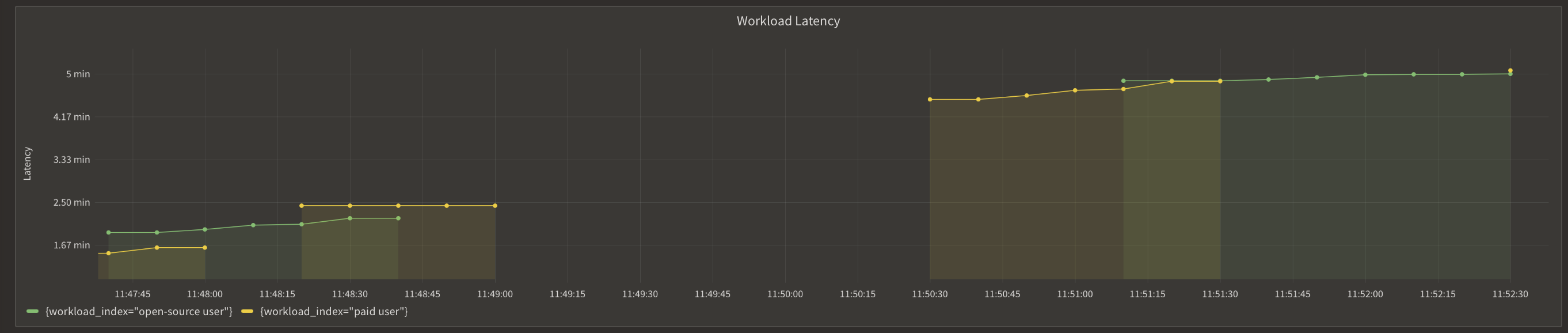
This realization led us to acknowledge that despite Mistral's user-friendly deployment process, the GPU limitation significantly hinders the performance of concurrent generative AI workloads. In the real world, the number of GPUs will be much higher, but so will the number of concurrent users. Therefore a degradation in user experience and performance issues cannot be neglected.
Maximizing Efficiency with FluxNinja Aperture's Concurrency Scheduling Feature
FluxNinja Aperture’s Concurrency Scheduling feature allows practitioners to set the maximum concurrent requests that a system can handle at a given time. Any request exceeding concurrency will get queued by Aperture. Queuing can be done on a priority basis, which can be defined based on the specific business criteria, and passed via the Aperture SDK. By defining priorities, organizations can ensure that crucial or revenue-generating requests are processed promptly and efficiently. For example, when our application caters to two tiers of users – paid and open source – prioritizing paid requests during periods when Mistral's computation was slowing down significantly enhanced overall business efficiency. Based on the priority, Aperture will bump up high-priority requests over low-priority ones. This feature is designed to keep the user experience optimal, ensure stable operations, and prevent overloading.
Let's take a look at how easily the Aperture SDK can be integrated with an existing App.
Aperture SDK Integration
FluxNinja Aperture has a ready-to-use TypeScript SDK that can be integrated and used within minutes.
After signing up on Aperture Cloud to start our 30-day free trial, and installing the latest version of the SDK in our repository, let's create an Aperture Client instance, passing the organization endpoint and API key, which can be found by clicking on the Aperture Tab within the Aperture Cloud UI.
Integration with Aperture SDK
The next step consists of setting up essential business labels to prioritize requests. In our case, requests should be prioritized by user tier classifications:
Defining Priorities
The following step is making a startFlow call to Aperture before sending a
request to Mistral. For this call, it is important to specify the control point
(mistral-prompt in our example) and the labels that will align with the
concurrency scheduling policy. The priority label is necessary for request
prioritization, while the workload label differentiates each request.
According to the policy logic designed to limit the number of concurrent
requests sent to Mistral, Aperture will, on each startFlow call, either give
precedence to a critical request or queue a less urgent one when approaching the
concurrency limit. The duration a request remains in the queue is determined by
the gRPC deadline, set within the startFlow call. Setting this deadline to
120000 milliseconds, for example, indicates that the request can be queued for
a maximum of 2 minutes. After this interval, the request will be rejected.
Once the startFlow call is made, we send the prompt to Mistral and wait for
its response. Excess requests are automatically queued by Aperture. It is
important to make the end call after processing each request to send telemetry
data that would provide granular visibility for each flow.
Start & End Flow Functionality
Aperture Cloud Policy
Now, the final step is to set up a Concurrency Scheduling Policy within the Aperture Cloud UI.
Navigate to the Policies tab on the sidebar menu, and select Create Policy
in the upper-right corner. Next, choose the Rate Limiting blueprint, select
Concurrency, and complete the form with these specific values:
Policy name: Unique for each policy, this field can be used to define policies tailored for different use cases. Set the policy name toconcurrency-scheduling-test.Limit by label key: Determines the specific label key used for concurrency limits. This parameter becomes essential for more granular concurrency limiting use cases such as, per-user limiting where a parameter like theuser_idcan be passed. For now, we will test global concurrency limiting, we will leave the label as it is.Max inflight duration: Configures the time duration after which flow is assumed to have ended in case the end call gets missed. We'll set it to60sas an example.Max concurrency: Configures the maximum number of concurrent requests that a service can take. We'll set it to2as an example.Priority label key: This field specifies the label that is used to determine the priority. We will leave the label as it is.Tokens label key: This field specifies the label that is used to determine tokens. We will leave the label as it is.Workload label key: This field specifies the label that is used to determine the workload. We will leave the label as it is.Control point: It can be a particular feature or execution block within a service. We'll usemistral-promptas an example.
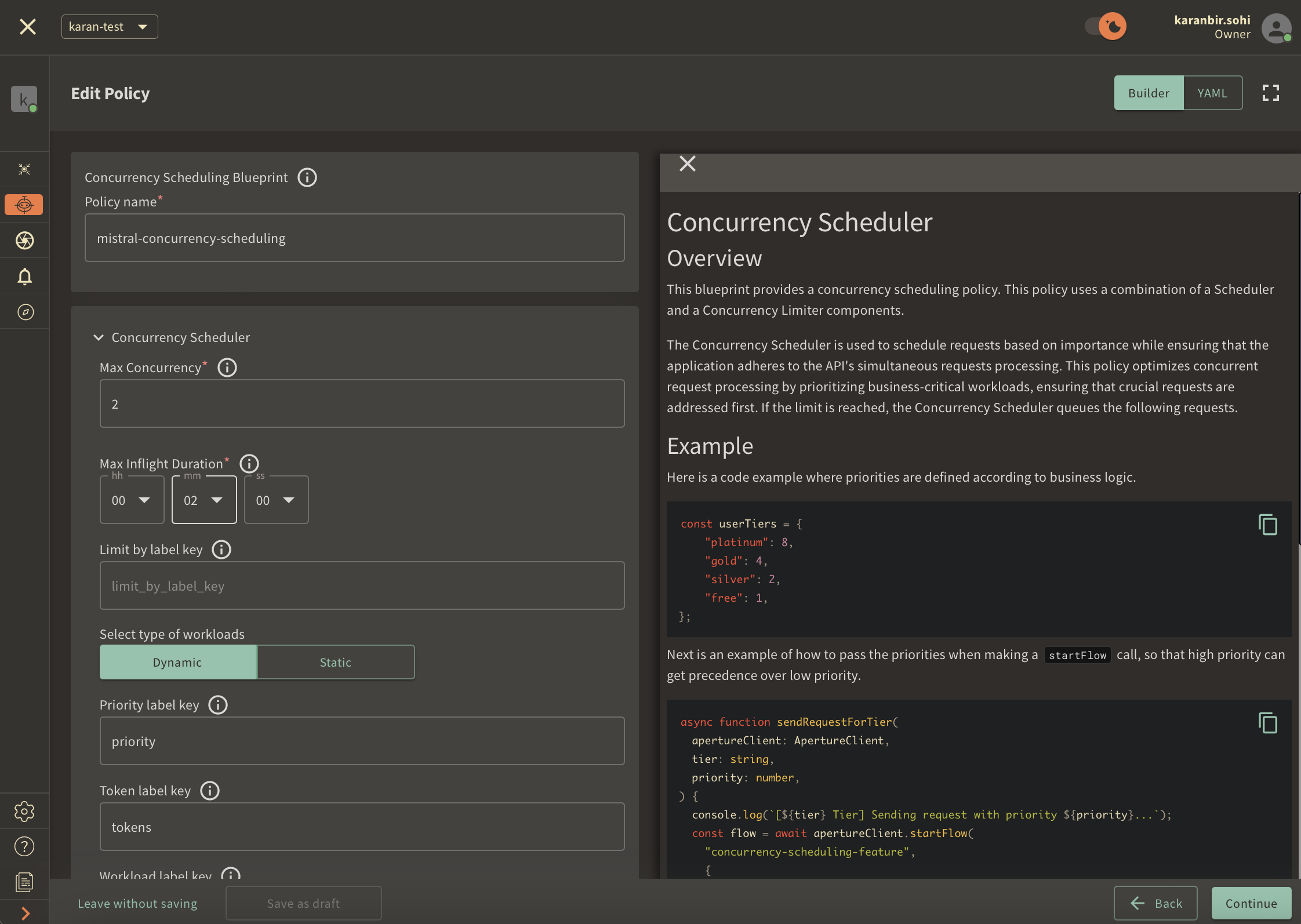
Once you've completed these fields, click Continue and then Apply Policy to
finalize the policy setup.
The integration with the Aperture SDK and this policy will make sure that every time a request is sent to Mistral, Aperture will either send it or queue it based on the concurrency and priority labels provided.
Monitoring Concurrent Requests Sent to Mistral
We concurrently ran the same script with 5 users for each tier and a total of 250 prompts as mentioned earlier. But this time, we saw quicker response times, particularly for paid users, due to assigning a higher priority.
Aperture's ability to collect advanced telemetry data allowed us to see how workloads performed, how many requests got queued, and what the latency of processing workloads was.
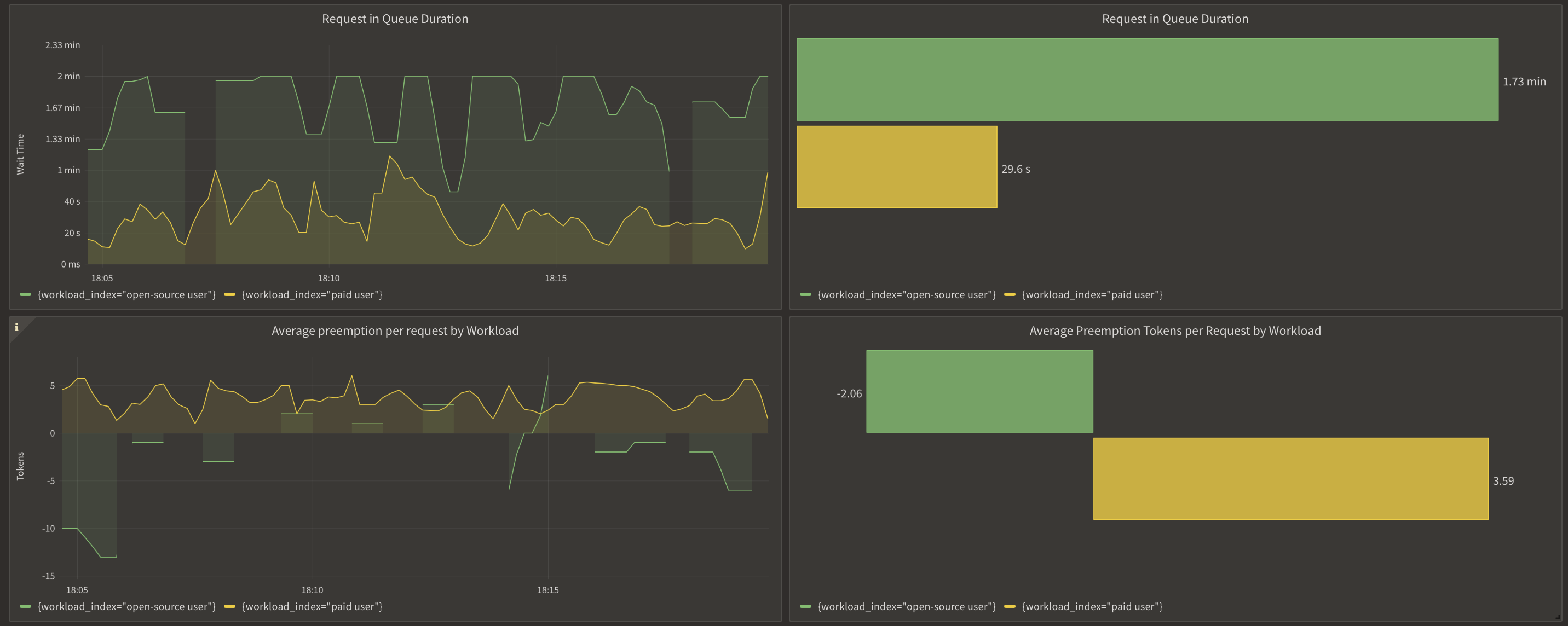
Here is the graph that we observed:
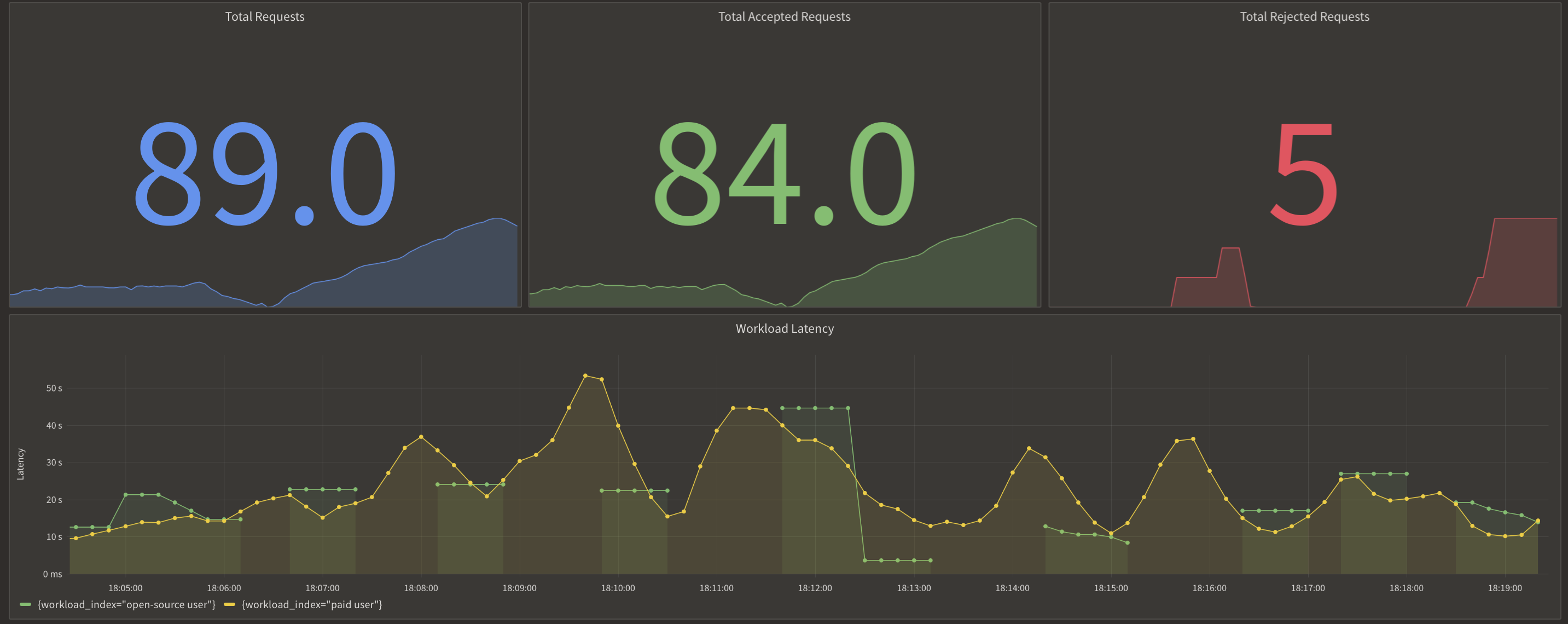
Here is the queueing and prioritization of requests when the max concurrency is met, and how paid requests get bumped up in the queue.
Conclusion
In this blog post, we delved into the potential of the open-source model Mistral for building AI-driven apps and addressed the challenge of slow responses resulting from GPU limitations when handling multiple concurrent requests. This issue significantly impacts user experience and performance, two critical factors for revenue generation and user acquisition in today's competitive market.
To address this challenge, we introduced FluxNinja Aperture's Concurrency Scheduling and Request Prioritization features, essential to managing Mistral's workload while ensuring optimal user experience and performance. With FluxNinja Aperture, practitioners can build cost-effective AI-driven applications without incurring excessive infrastructure expenses during demand surges. Simultaneously, they maintain smooth operations.
By leveraging FluxNinja Aperture, you'll be well-positioned to optimize resource utilization, ensuring your AI applications not only meet but exceed expectations in terms of performance and user experience.
For a more in-depth understanding of FluxNinja Aperture, we invite you to explore our Documentation or sign up for a 30-day trial. Additionally, join our vibrant Discord community to discuss best practices, ask questions, and engage in insightful discussions with like-minded individuals in the AI development field.